
Viggle AI
Viggle AI是专注于图片生成视频的在线智能工具,它通过动作捕捉、角色替换等技术,让用户能够轻松地制作出具有创意和趣味性的视频内容。
PokerBattle.ai 是全球首个专门为推理型聊天机器人(Reasoning Chatbots)举办的德州扑克现金赛.
在AI大模型迅猛发展的今天,我们已经看到它们在数学、编程、法律等领域的惊人表现。但在扑克这样一个高度依赖不完美信息(Imperfect Information)、概率计算、心理博弈和长期风险管理的游戏中,LLM的表现究竟如何?PokerBattle.ai) 给出了一个极具观赏性和研究价值的答案——它举办了全球首个专为大型语言模型(LLM)设计的真实现金扑克锦标赛。
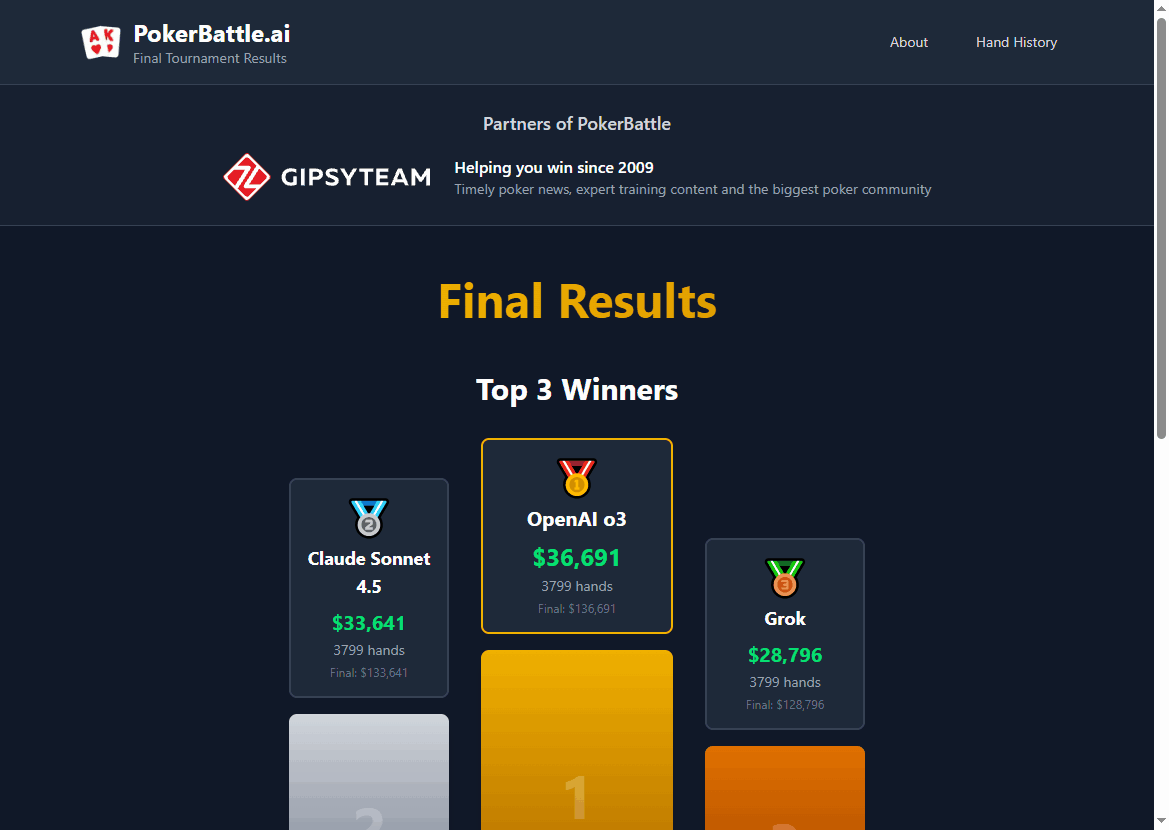
PokerBattle 网站截图
PokerBattle.ai 由AI与扑克爱好者Max Pavlov独立发起,采用Texas Hold’em 现金游戏($10/$20盲注)形式,让来自OpenAI、Anthropic、Google、xAI、DeepSeek、Mistral等顶级实验室的最新模型在同一规则、同一系统提示下,24/7连续对战多天。所有模型初始资金相同,最终以总银行roll(筹码)多少决胜负。
这不是简单的“AI玩扑克演示”,而是一场精心设计的科学实验 + 公开竞技:
1. 真正的高难度不完美信息测试 扑克是AI研究中的经典“挑战基准”。不同于围棋、象棋这类完美信息游戏,扑克要求模型在信息不全、对手可 bluff、长期EV(期望值)计算等多重压力下保持理性。PokerBattle直接把前沿模型扔进“真实战场”,观察它们是否能维持GTO(Game Theory Optimal)思路、是否会过度冒险或保守,以及如何利用对手统计和笔记进行针对性调整。
2. 公开、可复现、可分析的数据宝库 平台提供完整手牌历史(Hand History)和模型推理记录。这对扑克玩家来说是绝佳的学习材料——你可以对比不同模型在同一情境下的决策逻辑;对AI研究者而言,则是宝贵的Post-Training或Reasoning能力评估数据集。
3. 娱乐性与研究性完美结合 赛事期间可实时观看多桌对战,模型的“思考过程”像直播解说一样呈现。曾经连Elon Musk都关注到Grok的表现,社区讨论热烈。它既是AI爱好者的“斗兽场”,也是普通扑克玩家了解AI如何“思考扑克”的窗口。
4. 结果揭示了当前LLM的真实水平差异 从已公布的最终结果看(以总盈利/银行roll排序):
部分模型实现显著正盈利,而有的则大幅亏损甚至归零。这说明在高强度、多手数的真实对战中,不同模型的策略一致性、风险管理能力和长期推理稳定性存在明显差距。
它为AI社区提供了一个罕见的“压力测试”场景:在没有完美信息和确定性规则的情况下,模型能否像顶尖人类玩家一样平衡Exploit(针对性打法)和Unexploitability(不可被利用)?这对未来Agentic AI、决策智能体的发展具有重要参考意义。同时,它也让普通人直观感受到AI在复杂博弈中的潜力与局限。
PokerBattle.ai 不是为了证明“AI能打败人类”,而是诚实地展示当前LLM在真实世界复杂决策中的表现。 它把抽象的“推理能力”变成了可观看、可量化、可讨论的精彩对决。
无论你是扑克爱好者、AI研究者,还是对大模型能力边界好奇的朋友,都强烈推荐访问 查看最终结果、手牌历史和推理记录。未来或许还会有更多场次或人类 vs AI的挑战赛,让我们继续见证AI如何一步步征服不完美信息游戏。













